
C++中的右值引用与移动语义
开题发表暴论:C++中的移动语义(Move Semantics)本质上就是手动触发一次 Rust 中的所有权转移(Ownership Transfer)
Why we need it ?
在 C++11 之前,如果想把一个对象(比如一个巨大的 std::vector 或 std::string)从一个变量传递给另一个变量,或者从函数返回,编译器通常会执行深拷贝(Deep Copy)。
- 拷贝构造: 分配新内存 -> 复制数据 -> 销毁旧对象。
- 浪费: 如果旧对象马上就要被销毁(比如它是一个临时变量),那么“复制一份再销毁原件”是非常愚蠢且昂贵的。
而移动语义允许我们直接“窃取”临时对象的资源(如堆内存指针),而不是复制它们。
左值 vs 右值
想要了解移动语义,我们需要先探究左值与右值的区别。
-
左值(Lvalue):
- 有名字,有地址,是持久的对象。
也就是是说,我们是可以对左值进行取地址&x。
For an example :int a = 10,其中,a就是一个左值。
- 有名字,有地址,是持久的对象。
-
右值(Rvalue):
- 没有名字,没有地址,将亡的对象。(也就是临时对象)
右值通常是字面量,表达式求值的结果,或者函数返回的非引用对象。
For an example:10,x+y,func_return_obj()。
- 没有名字,没有地址,将亡的对象。(也就是临时对象)
其实就跟他们的名字一样,一个赋值语句:int a = 10
在左侧的就是左值,右侧的就是右值。
右值引用
在 C++ 11 中,引入了一种新的引用类型,为右值引用 ,用双&表示。
例如:
int& a //为左值引用,只能绑定到左值
int&& a //为右值引用,只能绑定到右值int a = 10;
int& ref1 = a; // 合法:左值引用绑定左值
// int&& ref2 = a; // 非法!a 是左值,不能绑定到右值引用
int&& ref3 = 10; // 合法:10 是右值那么右值引用有什么作用呢?
右值引用,是在告诉编译器:“这是一个即将销毁的临时对象,你可以随意修改它,或者窃取它的资源,反正没人会再用到它了。”
移动语义
回到我们的正题,什么是移动语义呢?
移动语义就是利用右值引用重载构造函数和赋值运算符,实现所谓的“资源窃取”。
Example
假设我们有一个负责管理堆内存的类Buffer。
如果用之前的拷贝构造函数:
// const Buffer& 表示我不修改源对象,我只读
Buffer(const Buffer& other) {
// 1. 分配新内存
data = new int[other.size];
// 2. 复制数据 (慢!)
memcpy(data, other.data, other.size);
size = other.size;
}而如果我们使用移动语义来实现移动构造函数:
// Buffer&& 表示 other 是个将亡值,我可以修改它
Buffer(Buffer&& other) noexcept {
// 1. 直接窃取指针 (极快!)
data = other.data;
size = other.size;
// 2. 重要:将源对象的指针置空
// 否则 other 析构时会 delete 这块内存,导致我们也悬空 (Double Free)
other.data = nullptr;
other.size = 0;
}Benchmark
或许你会说: memcpy 本身就很快啊,二者之间能有多少差距?
那么就让我们写一个Benchmark吧!
这里我直接使用写好的脚本,你可以在这里看到。
我们将测试场景设定为:把大量对象从一个 vector 转移到另一个 vector。
为了让对比纯粹,我做了两个关键设置:
- 预先分配内存 (
reserve):排除std::vector自身扩容分配内存的时间,只测元素的构造/拷贝时间。 - 数据量足够大:每个对象管理 4MB (1024*1024 个 int) 的内存,重复 1000 次。
最后,他在我的电脑上跑出了下面的成绩:
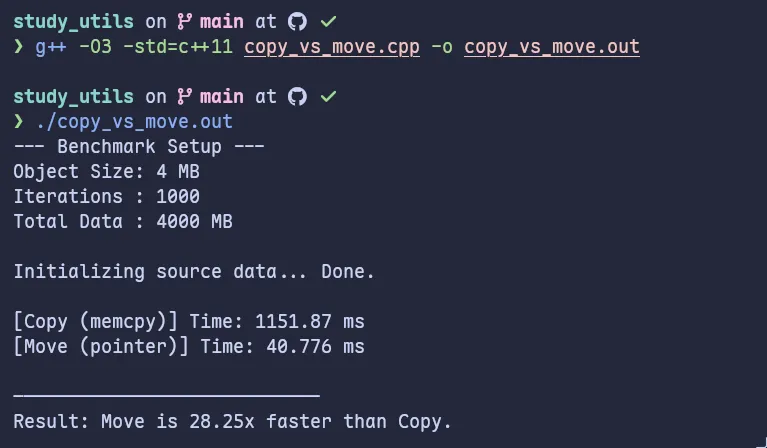
可以看到,利用移动构造,我们比拷贝构造快了整整28.25倍!
为什么更快?
的确, memcpy很快,但是一辆法拉利再怎么快也跑不过瞬移啊。
分开来讲,主要有三个因素:
算法复杂度(O(N) vs O(1))
这是最本质的区别。
- Copy (基于 memcpy): 如果你有一个 1GB 的
Buffer对象:memcpy必须逐个字节地从源地址读出,写入目的地址。CPU 必须搬运 10^9 个字节。 耗时与数据量成正比(线性关系,O(N))。 - Move (基于指针交换): 不管你的
Buffer是 1KB 还是 100GB,移动构造函数只做一件事:赋值指针。 在 64 位系统上,指针就是 8 个字节。耗时是常数,几乎瞬间完成(O(1))。
我们来做一个比喻:
- Copy (
memcpy): 你有一房子书。你要搬家。你把每一本书都打包,运到新房子,再拆包摆好。虽然你动作很快(SIMD),但书越多,你越累。 - Move: 你直接把新房子的钥匙换成旧房子的钥匙。你人根本不用动书,书就在那儿,归属权变了而已。
这也就是我开局暴论的由来
伴随的内存分配成本 (System Call)
memcpy 并不是独立存在的,它前面通常跟着一个 new
// Copy Constructor
data = new int[other.size]; // <--- 昂贵的系统调用!
memcpy(data, other.data, size); // <--- 搬运数据- 内存分配 (
malloc/new):这是一个很重的操作。操作系统需要查找空闲堆块、更新堆表、处理并发锁,甚至触发缺页中断(Page Fault)。 - Move:不需要分配新内存,直接接管现有的内存块。
对于小对象,new 的开销甚至可能比 memcpy 还要大。
缓存局部性 (Cache Locality)
- Copy:
memcpy涉及大量的内存写入。当你写入一块全新的大内存(刚才new出来的)时,这块内存可能不在 CPU 的 L1/L2 缓存中。这会造成大量的 Cache Miss,CPU 被迫等待内存总线,导致流水线停顿。 - Move: 仅仅修改栈上的几个指针变量,这些变量极大概率已经在 L1 缓存或者寄存器里了。
总结
说白了,并不是memcpy很烂,而是深拷贝本身就是一个极其昂贵的操作。
对比: 拷贝是“造一栋一模一样的房子”;移动是“把房子的钥匙给你,我走人”。
std::move 到底做了什么?
这是最容易误解的地方。std::move 根本不移动任何东西
它只是一个强制类型转换(Cast)。它把一个左值(Lvalue)强制转换成一个右值引用(Rvalue Reference, T&&)。
- 作用: 它的意思是告诉编译器:“虽然
x是个左值(有名字),但我向你保证,我以后不再用它了,你可以把它当做右值(临时对象)来处理,去调用它的移动构造函数吧!”
For a example:
std::string a = "Hello World";
std::string b = a; // 调用拷贝构造,a 依然有效
std::string c = std::move(a); // 调用移动构造,a 变为空字符串(资源被 c 偷走了)
// 此时访问 a 是安全的,但它是未定义状态(通常为空),不要再依赖它的值。
...tic.maredevi.fun/piclist/20251224212006062.png) About C++ 什么? 还有C++ 的事? 是的,虽然并没有像rust一样在标准库中存在,而是以一种概念的形式出现。而这恰好又与我们在[[C++中的右值引用与移动语义]]提到的移动语义相关:Cpp 中的 Pin 主要通过禁用移动语义来实现。 实现方式 在 C++...